> For the complete documentation index, see [llms.txt](https://riboseyim.gitbook.io/perf/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://riboseyim.gitbook.io/perf/devops-opentracing.md).
# 分布式追踪系统体系概要
## 摘要
* Key Words: metrics、logging、tracing
* Google Dapper Family : Uber Jaeger、淘宝 EagleEye、微博 Watchman、京东 CallGraph、美团 MTrace
* 数据可视化 | Exporters
This article is part of an **Distributed Tracing and Monitoring System** tutorial series. Make sure to check out my other articles as well:
* [DevOps 漫谈:开源分布式跟踪系统 OpenCensus](https://riboseyim.github.io/2018/04/27/DevOps-OpenCensus)
* [DevOps 漫谈:分布式追踪系统标准体系](https://riboseyim.github.io/2018/05/18/DevOps-OpenTracing/)
## 绪论
讨论分布式追踪技术,首先需要明确的是:什么是跟踪 ?
### metrics
度量(metrics)的特征是聚合: 它们是在一段时间内组成单一逻辑标尺、计数器或直方图的跨度。例如:HTTP 请求的数量可以建模为计数器(counter), 其更新逻辑很简单,只需通过加法聚合; 如果设定一段持续的观察时间,请求数可以被建模成一个直方图。[《基于Ganglia实现服务集群性能态势感知》](https://riboseyim.github.io/2016/11/04/OpenSource-Ganglia/) 介绍的就是以记录度量为主的故障监控系统。
### logging
日志(logging)的特征是处理离散事件。按照事件发生的源可以分为 Application Events、System Events、Service Events、DNS Events 等。通常也包含针对原始记录的处理过程,例如:通过 Syslog 将应用程序调试或错误消息发送到 Elasticsearch ; 审计记录通过 Kafka 将数据推送到类似 BigTable 的数据池; 从服务调用中提取特定的请求元数据, 并发送错误跟踪服务(例如 [NewRelic](https://ruby-china.org/topics/22379))。
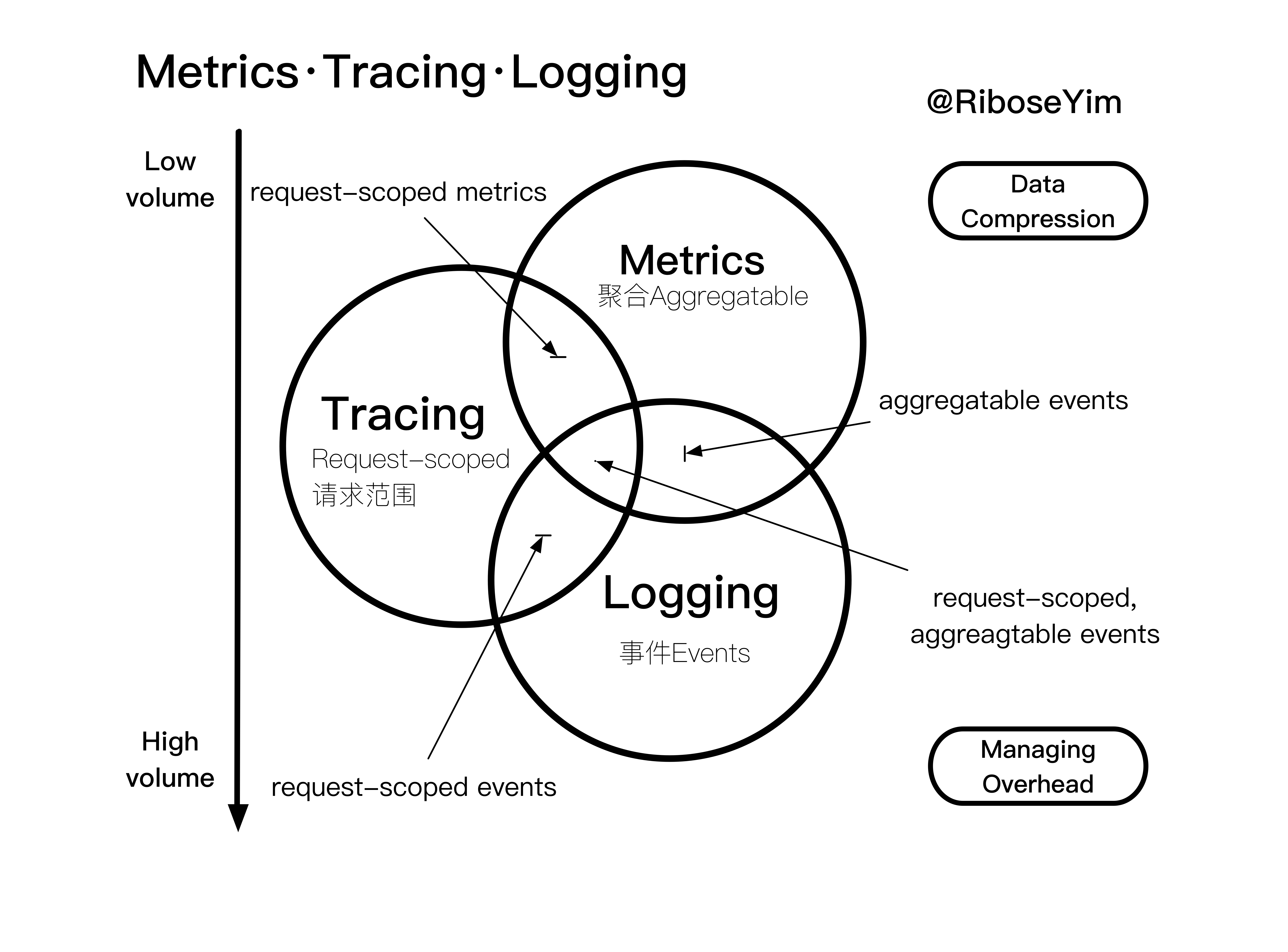
### tracing
跟踪(tracing)的特征:跟踪处理的是请求范围内的信息(request-scoped),例如 SQL 语句在数据库的实际执行时间或 HTTP 请求耗时。以 DTrace & SystemTap 为代表的 [动态追踪技术](https://riboseyim.github.io/2016/11/26/DTrace/) 基于操作系统内核,不需要埋点就可以提供高级性能分析和调试功能。但是在分布式架构场景中也有一些不足,例如某些功能需要多次调用 RPC 远程服务,这些服务分布在多台不同的 host/vm/docker 中,如果需要测量该功能响应的完整持续时间就有难度。
### 示例(Use OpenCensus with OpenZipkin)
[OpenCensus](https://riboseyim.github.io/2018/05/18/DevOps-OpenTracing/) 作为埋点 API ,导出 tracing data 到 OpenZipkin,由 Zipkin 的 Web UI 提供数据展示和交互能力,可以很清晰地看到函数调用顺序和耗时。从理解系统行为的角度上说,与动态追踪技术中的火焰图(flame graph)有异曲同工之妙。
* 串行调用函数方法,包括网络访问和持久化操作

* 示例(OpenCensus with OpenZipkin):并行调用函数方法(Go routine)

## Google Dapper Family
讨论分布式跟踪,就一定会谈到 Dapper —— Google 公司研发并应用于自己生产环境的一款跟踪系统(设计之初参考了一些 Magpie 和 X-Trace 的理念 )。Dapper 不仅为业内提供了非常有参考价值的实现,同步发表论文的也成为了当前分布式跟踪系统的重要理论基础。Google Dapper 的理念影响了一批分布式跟踪系统的发展,例如 2012 年,Twitter 公司严格按照 Dapper 论文的要求实现了 Zipkin (Scala 编写,集成到 Twitter 公司自己的分布式服务 Finagle );Uber 公司基于 Google Dapper 和 Twitter Zipkin 的灵感,开发了开源分布式跟踪系统 Jaeger。
* [《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure|Google Technical Report dapper-2010-1, April 2010》](https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/papers/dapper-2010-1.pdf)
OpenTracing 通过提供平台无关、厂商无关的API,使得开发人员能够方便的添加(或更换)追踪系统的实现。 OpenTracing 提供了用于运营支撑系统的和针对特定平台的辅助程序库。除了 API 之外,一个完整的分布式追踪系统还需要包括数据存储、支持代理转发、用户友好的 WebUI 等特性,例如:Zipkin 专注于 tracing 领域;Prometheus 开始专注于 metrics,同时可能会发展更多的 tracing 功能,但不太可能深入 logging 领域;基于 ELK 之类的日志系统专注于 logging 领域,但也可能集成其他领域的特性。总之,各式各样的分布式追踪系统都是以 tracing 为基础,同时根据自己的需要在其他两个领域各有所侧重而已。
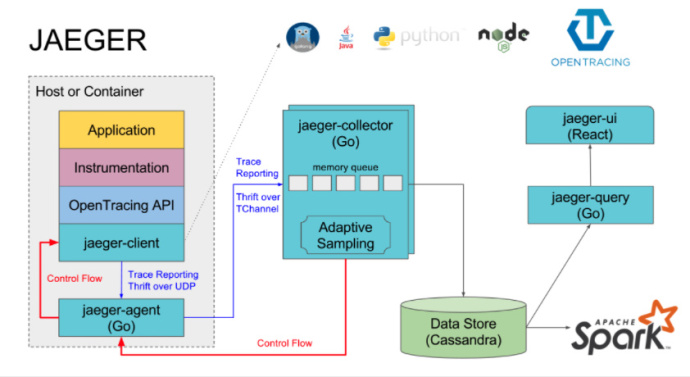
### Uber Jaeger
[Uber Jaeger](http://www.infoq.com/cn/articles/evolving-distributed-tracing-at-uber-engineering) 是 Uber 工程团队开源的分布式追踪系统。自 2016年 起,Jaeger 在 Uber 内部实现大范围应用。Uber 同时开发了一种适用于 RPC 的网络多路复用和框架协议 —— [TChannel | Support: Node.js,Python,Go,Java](https://github.com/uber/tchannel),该协议融入了分布式追踪能力。
TChannel 协议规范在二进制格式中直接定义了追踪字段:“ spanid:8 parentid:8 traceid:8 traceflags:1 ”。
* jaeger-client:支持多种语言的客户端库,如Go, Java, Python等语言
* jaeger-agent:客户端代理负责将追踪数据转发到服务端,这样能方便应用的快速处理,同时减轻服务端的直接压力;另外可以在客户端代理动态调整采样的频率,进行追踪数据采样的控制
* jaeger-collector:数据收集器主要进行数据收集和处理,从客户端代理收集数据进行处理后持久化到数据存储中
* 数据存储:目前支持将收集到的数据持久化到 Cassandra 、 Elasticsearch
* jaeger-query:主要根据不同的条件到数据存储中进行搜索,支撑前端页面的展示
* jaeger-ui:一个基于 React 的前端 webui
* jaeger spark: 是一个基于 Spark 聚合数据管道,用以完成服务依赖分析
### 淘宝 EagleEye(鹰眼)
[EagleEye(鹰眼)](http://jm.taobao.org/2014/03/04/3465/) 是Google 的分布式调用跟踪系统 Dapper 在淘宝的实现。主要特点是通过每台应用机器上的 Agent 实时抓取 EagleEye 日志,按照日志类型不分别处理:
* 全量原始日志直接存储到 HDFS ;创建 MapReduce 任务完成调用链合并、分析和统计;
* 有实时标记的原始日志存储到 HBase ;
* 业务日志:一部分会被直接处理存储到 HBase,有一部分会作为消息发送出去,由特定的业务系统订阅处理;
* 调用实时统计,提供分钟级别的实时链路调用视图,辅助故障定位。
### 国内其他衍生系统
* [微博 Watchman](http://www.infoq.com/cn/articles/weibo-watchman):微博平台的链路追踪及服务质量保障系统。watchman-aspect 组件通过异步日志(async-logger)在各个节点上输出日志文件;以流式的方式处理数据,watchman-prism 组件(基于 Scribe),将日志推送到 watchman-stream 组件(基于Storm), 根据需求进行聚合、统计等计算(针对性能数据),规范化、排序(针对调用链数据),之后写入 HBase 。
* [京东 CallGraph](http://zhuanlan.51cto.com/art/201701/528304.htm):全局 TraceID 的调用链。核心包(完成埋点逻辑,日志存放在内存磁盘上由 Agent 收集发送到JMQ)、JMQ(日志数据管道)、Storm(对数据日志并行整理和计算)、存储(实时数据存储JimDB/HBase/ES,离线数据存储包括HDFS和Spark)、CallGraph-UI(用户交互界面)、UCC(存放配置信息并同步到各服务器)、管理元数据(存放链路签名与应用映射关系等)。日志格式:固定部分(TraceID、RpcID、开始时间、调用类型、对端IP、调用耗时、调用结果等)、可变部分。
* [美团 MTrace](https://tech.meituan.com/mt-mtrace.html):美团点评内部的分布式会话跟踪系统。基于全局 TraceID 的调用链,客户端与后端服务之间有一层 Kafka,实现两边工程的解耦。实时数据主要使用 Hbase ,traceID 作为 RowKey;离线数据主要使用 Hive,可以通过 SQL 进行一些结构化数据的定制分析。
* [CN105224445B | WO2017071134A1 | 分布式追踪系统| 北京汇商融通信息技术有限公司 | 2015-10-28](https://patents.google.com/patent/WO2017071134A1/zh)
* **不完全统计**
| 名称 | 原理 | 客户端 | 依赖分析 | 存储 | 可视化 |
| --------------- | ------- | ---------------------------------------------- | --------- | -------------------------------- | -------------------------- |
| Google Dapper | TraceID | ----- | ----- | ----- | ----- |
| OpenTracing | TraceID | go,java,python,js,objective-c,c++ | ----- | ----- | ----- |
| OpenCensus | TraceID | go,java,python,C++,.Net,js,Erlang | ----- | ----- | no web-ui,Support Exporter |
| Uber Jaeger | TraceID | java,go,python
Support Agent Proxy
| Spark | Cassandra、ES | React Web-ui |
| 淘宝 EagleEye(鹰眼) | TraceID | yes | MapReduce | HDFS(全量)
HBase(实时)
| yes |
| 微博 Watchman | 日志 | watchman-aspect | Storm | HBase | yes |
| 京东 CallGraph | TraceID | Agent->JMQ | Storm | JimDB(实时)
ES、Spark(离线)
| yes |
| 美团 MTrace | TraceID | Agent-> Kafka
Support Agent Proxy
| Storm | HBase(实时)
Hive(离线)
| yes |
## 管理负载 Managing Tracing Overhead
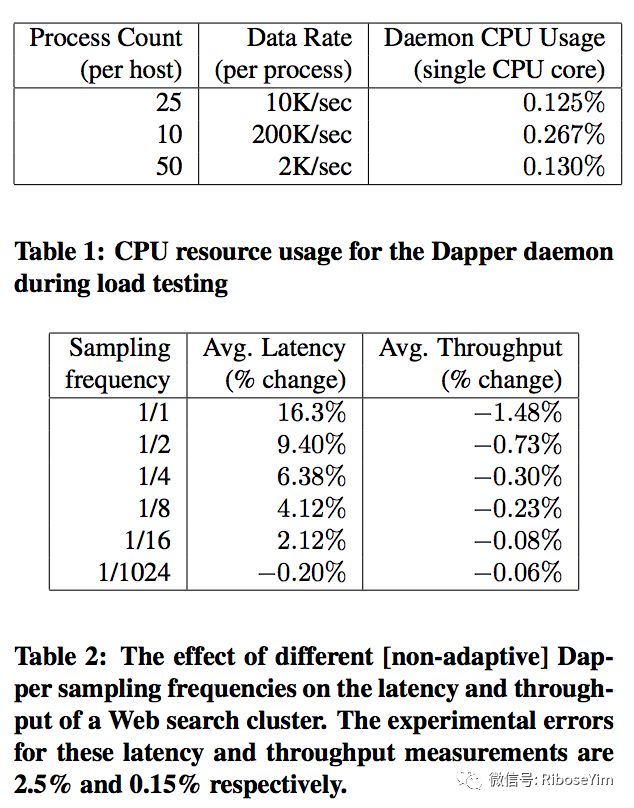
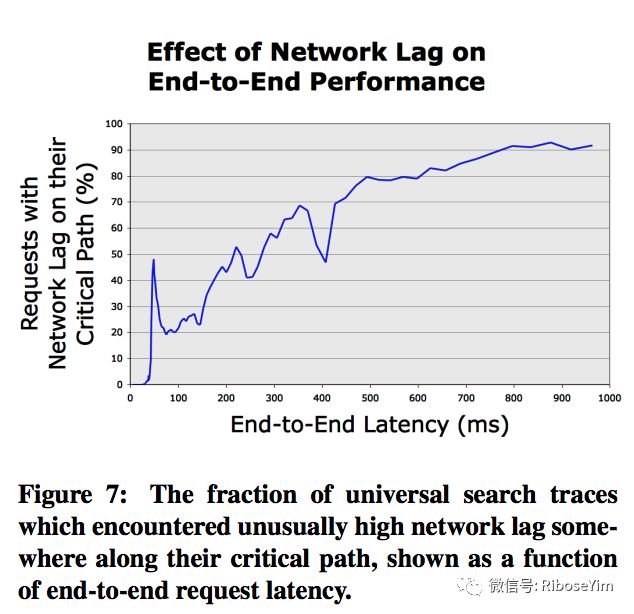
目前多数分布式追踪系统采用异步写入日志、建立缓冲存储(基于内存或者内存数据库)、设置采样阈值策略(包括一定情况下直接丢弃)的方式控制追踪负载。Google Dapper 公布的性能损耗测评数据如下:
**淘宝 EagleEye** :1)专属日志输出实现,日志异步写入来避免 hang 住业务线程,可调节日志输出缓冲大小,控制每秒写日志的 IO 次数等。2)全局采样开关,在运行期控制调用链的采样率(根据 TraceId 来决定当前的这一次访问日志是否输出)。比如采样率被设置为 10,一部分调用链日志完全不输出,只有 hash(traceId) mod 10 的值等于0的日志才会输出。例如核心入口的调用量样本空间足够大(每日百万次以上级别),假设统计误差 0.1% ,即使开启1/10的采样总和误差也是可以接受的。
**微博 Watchman**:如某个服务由于瞬时访问高峰,造成底层资源压力变大从而服务响应时间变长,控制策略可以根据设定随机丢弃后续的请求,如果情况加剧就会自动降级该服务,保证核心服务路径。
## 扩展阅读:动态追踪技术
* [动态追踪技术(一):DTrace 导论](https://riboseyim.github.io/2016/11/26/DTrace/)
* [动态追踪技术(二):strace+gdb 溯源 Nginx 内存溢出异常 ](https://mp.weixin.qq.com/s?__biz=MjM5MTY1MjQ3Nw==\&mid=2651939588\&idx=1\&sn=35f71c5f88d1edf23cb2efc812ab8e6c\&chksm=bd578c168a20050041c08618281691f0111f61c789097a69095933057618637fc54817815921#rd)
* [动态追踪技术(三):Tracing Your Kernel Function!](https://riboseyim.github.io/2017/04/17/DTrace_FTrace/)
* [动态追踪技术(四):基于 Linux bcc/BPF 实现 Go 程序动态追踪](https://riboseyim.github.io/2017/06/27/DTrace_bcc/)
* [动态追踪技术(五):Welcome DTrace for Linux](https://riboseyim.github.io/2018/02/16/DTrace-Linux/)
## 参考文献
* [OpenTraing 文档 | 中文 ](https://wu-sheng.gitbooks.io/opentracing-io/content/)
* [The difference between tracing, tracing, and tracing](https://medium.com/opentracing/the-difference-between-tracing-tracing-and-tracing-84b49b2d54ea)
* [Using OpenTracing with Istio/Envoy](https://medium.com/jaegertracing/using-opentracing-with-istio-envoy-d8a4246bdc15)
* [优步分布式追踪技术再度精进](http://www.infoq.com/cn/articles/evolving-distributed-tracing-at-uber-engineering)
* [开放分布式追踪(OpenTracing)入门与 Jaeger 实现](https://zhuanlan.zhihu.com/p/34318538)
* [Github | CNCF Jaeger, a Distributed Tracing System](https://github.com/jaegertracing/jaeger)
* [OpenTracing: Jaeger as Distributed Tracer](https://sematext.com/blog/opentracing-jaeger-as-distributed-tracer/?utm_source=getresponse\&utm_medium=email\&utm_campaign=devopslinks\&utm_content=DevOpsLinks+%23112:+Jenkins+Scripted+Pipelines,+The+State+Of+Stateful+Apps+on+K8S+%26+Never+Write+Your+Own+Database)
* [Distributed tracing at Pinterest with new open source tools](https://medium.com/@Pinterest_Engineering/distributed-tracing-at-pinterest-with-new-open-source-tools-a4f8a5562f6b)
* [Instrumenting a Go application with Zipkin](https://medium.com/devthoughts/instrumenting-a-go-application-with-zipkin-b79cc858ac3e)
* [分布式跟踪系统(一):Zipkin的背景和设计](http://manzhizhen.iteye.com/blog/2348175)
* [分布式调用跟踪系统调研笔记](http://ginobefunny.com/post/learning_distributed_systems_tracing/)
* [Node.js Performance and Highly Scalable Micro-Services - Chris Bailey, IBM](https://www.youtube.com/watch?v=Fbhhc4jtGW4\&feature=youtu.be)
* [分布式会话跟踪系统架构设计与实践 | 美团点评技术团队 | 志桐 ·2016-10-14 18:13](https://tech.meituan.com/mt-mtrace.html)
* [Metrics, tracing, and logging | 2017 02 21](http://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html)
* [跟踪 skynet 服务间的消息请求及性能分析 | 云风的Blog](https://blog.codingnow.com/2018/05/skynet_trace.html)